C언어에서
1
int tmp[3];
위와 같은 방법으로 길이가 3인 배열을 선언했다고 가정하자. 그러면 해당 소스코드를 실행시켰을 때 int자료형의 3배만큼 길이의 연속적인 메모리 공간을 점유하게 된다.
그렇다면
1
int tmp[3][3];
위과 같이 다차원 배열을 선언한다면 어떻게 처리될까.
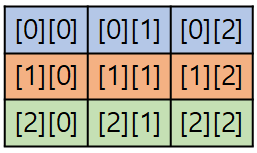
메모리는 자체는 일차원 선형구조이기 때문에 2차원 배열을 선언한다면 행 또는 열을 우선으로 처리할 것이라고 예상할 수 있다.
case.1

case.2
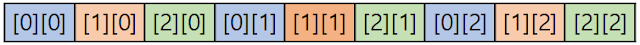
그래서 2차원 배열을 생성했을때 그 배열을 위의 두 그림중 하나의 형태로 메모리를 점유할 것으로 추측할 수 있다. 그렇다면 모든 언어가 동일한 기준으로 처리될까? 행우선 처리와 열우선 처리가 performance의 측면에서 유의미한 차이가 있을까에 대하여 실험해보고자 한다.
실험방법 개요
C, Java, Fortran, common Lisp, COBOL을 대상으로 2000*2000 행렬의 곱셈을 수행하여 행렬의 곱셈 방법별로 수행시간을 비교해본다. 코드의 실행시간을 측정하기 위해서는 각 언어에서 지원하는 시간 측정과 관련된 함수를 사용하며, 변수를 생성, 초기화, 해제 하는 과정은 시간측정 범위에 포함되지 않으며 순수한 행렬의 연산시간만을 측정한다.
행렬의 곱셈 연산
일반적인 행렬의 곱셈연산을 따지자면 곱셈의 대상 행렬이 정방행렬이 아닌 경우도 고려해야 하지만, 이번 실험의 경우에는 행렬의 곱셈이 목적이 아니라 각 프로그래밍언어의 성능과 특징을 파악하기 위한 것이기 때문에 편의상 정방행렬의 곱셈을 수행하도록 한다.

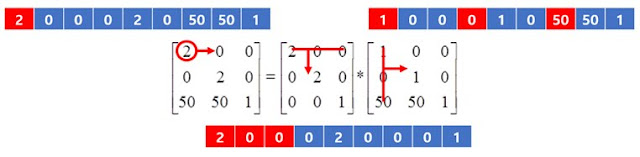
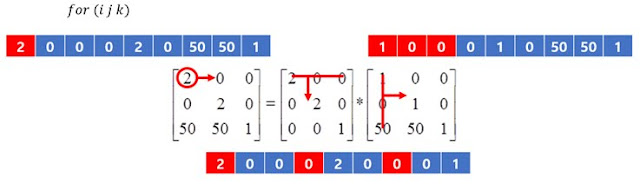
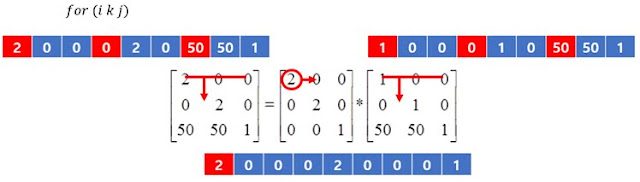
위 사진은 C언어에서 행렬의 곱셈을 수행하는 코드이다. 이 때 여기서 눈여겨 볼 점은 3개의 for문 제어변수인 i, j, k의 순서가 바뀌어도 정상적으로 곱셈연산이 수행된다는 것이다. 사람이 손으로 행렬의 곱셈을 계산할 때에는 여러 값을 곱하고 더해서 하나의 성분을 계산해 낸 후에 다른 성분을 계산하지만, 컴퓨터는 변수를 이용해서 여러개의 값을 기억할 수 있기 때문에 사람처럼 하나의 성분을 도출하는데에 집착하지 않고 효율적인 방법으로 계산을 수행할 수 있다.
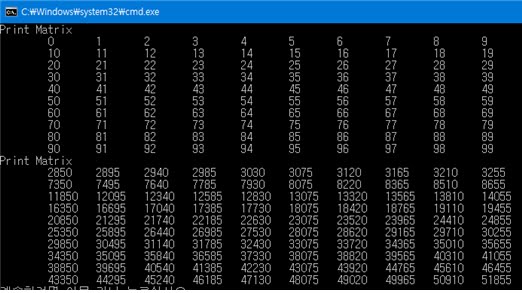
임의의 행렬 A(aij=i*10+j, i와 j는 음이 아닌 정수) 를 만들어서 A행렬을 한번 출력한 후에 A2를 계산하여 출력한 모습이다. 위에서 언급한 바와 같이 i,j,k의 순서를 바꿔도 모두 동일한 결과를 보여준다.
C언어에서의 행렬 연산
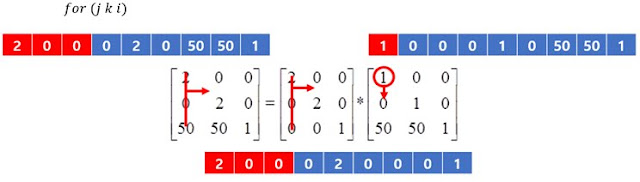
행렬의 곱셈을 수행하는 3중 for문은 각각 i, j, k의 제어변수를 사용하고 있는데, 이 때 가장 바깥의 제어변수가 i, 중간의 제어변수가 j, 가장 안쪽의 제어변수를 k로 두고 연산하는 것을 편의상 ijk방법이라 하겠다.
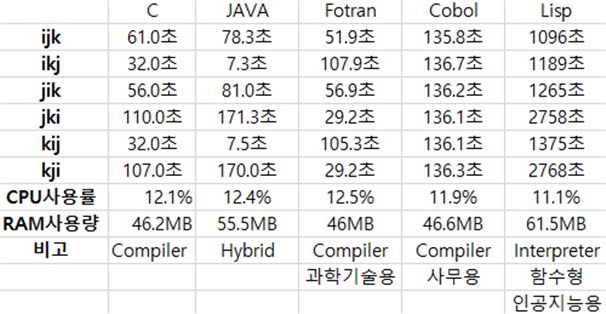
C언어에서 행렬곱셈의 실험결과는 다음과 같다.

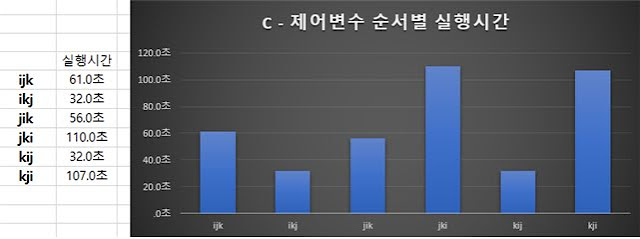
61초와 56초가 오차범위 내에서 동일한 성능이며, 110초와 107초가 또한 호차범위 내에서 동일한 성능이라고 가정하여 그림으로 비교해 보았다.
이 것은 약 60초의 결과를 보여준 ijk방법의 분석이다. 이 방법은 사람이 행렬을 계산할 때에 하나의 성분을 도출해 내는 것에 집중한 후에 다음 성분을 계산하는 것을 기반으로 만든 알고리즘이다. 이 행렬의 곱셈을 X=AB라고 할 때에 A행렬을 순회할 때에는 메모리의 처음부터 끝까지 순회하는 과정을 확인할 수 있지만, B행렬의 경우에는 연산에 필요한 데이터들이 드문드문 떨어져 있기 때문에 바람직하지 않은 경우이다. A행렬은 row major방법으로 순회하지만, B행렬은 column major방법으로 순회한다고 볼 수 있다.
다음으로는 약 30초의 실행시간을 보인 ikj방법의 분석이다. 결과 값을 저장하는 행렬과 가장 오른쪽의 행렬이 메모리의 처음부터 끝까지 순회하는 방향으로 진행하는 것을 확인할 수 있다. 게다가 가운데의 행렬도 메모리를 순차적으로 순회하기 때문에 row major언어에서 가장 특화된 방법을 모두 사용하는 것을 알 수 있다.
다음으로는 110초로 최악의 결과를 보여준 jki방법이다. data locality의 원리에 따라서 서로 연속적인 위치에 존재하는 데이터에 접근하는 것이 효과적인 방법이라는 것을 위의 2가지 결과 분석으로 알아낼 수 있었다. 하지만 이 것은 그 것과는 정 반대되게 띄엄띄엄 떨어진 데이터에 동시에 접근하는 것을 확인할 수 있다. 이 연산 방법은 column major방법이라는 것을 알아낼 수 있으며, C언어에서는 column major방법이 최악의 결과를 도출하는 것을 보아 C언어는 row major언어임을 확인할 수 있다.
Java에서의 행렬 연산


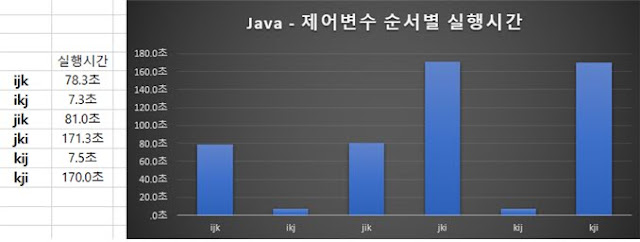
첫 번째 측정결과가 78초가 나온 것에 비교해서 두 번째 측정결과가 7초가 나와서 무언가 잘못됐다는 느낌을 받았으나, 여러가지를 점검하고 다시 테스트를 했음에도 불구하고 오류를 발견할 수 없어서 계속 측정하고 나서야 약간은 납득가는 결과를 얻을 수 있었다.
이 결과를 분석한 결과, C언어에서 측정한 것과 마찬가지로 ijk와 jik에서 중립적인 실행결과를 보여주었고, ikj와 kij에서 극단적으로 짧은 실행시간을 보였으며, jki와 kji에서 비정상적으로 긴 실행시간을 보이는 것을 확인할 수 있었다. C언어와 변화추이가 비슷하기 때문에 Java또한 row major언어임을 알 수 있으며, 방법마다 차이가 아주 크기 때문에 C언어보다 Java가 data locality의 영향을 더 크게 받는다는 것을 확인할 수 있었다.
Fortran에서 행렬 연산


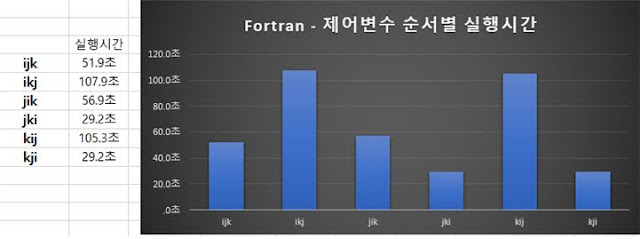
C언어에서 그림으로 분석한 것과 같이 분석한 결과는 다음과 같다.
row major언어에서 중간정도의 performance를 보인 ijk방법이다. 이 방법은 row major 특성의 연산이 포함돼 있고 column major의 연산도 포함되어 있기 때문에 중립적인 방법이라고 볼 수 있으며, row major연산과 column major연산의 중간정도의 성능을 보여준다. 따라서 Fortran에서도 중간정도의 결과를 보여주었다.
row major언어에서 가장 좋은 결과를 보여준 ikj방법이다. 그림으로 보아하니 column major에서는 접근해야 하는 데이터가 전부 따로따로 떨어져 있기 때문에 최악의 data locality가 형성되는 방법이다. 따라서 column major언어에서는 위의 방법으로 구현했을때 최악의 결과를 보여줄 것으로 예상할 수 있다. 실제로 Fortran에서 위의 방법을 사용했을 때 최악의 결과를 내는 것을 확인할 수 있었다.
반대로 row major언어에서 최악의 결과를 보여준 jki방법이다. 이 것도 마찬가지로 row major에서 최악이었으므로 column major에서는 최상의 결과를 낼 것이라는 것을 추측할 수 있다. 실제로 Fortran에서 실험한 결과 최상의 결과를 내는 것을 확인할 수 있다. 위의 실험결과를 종합 분석하면 Fortran은 column major언어임을 확인 할 수 있다.
Cobol에서 행렬 연산

특이한 점이 하나 있다면, C나 Java등은 배열을 만들었을때 index가 0부터 시작하지만, Cobol은 1부터 시작한다.
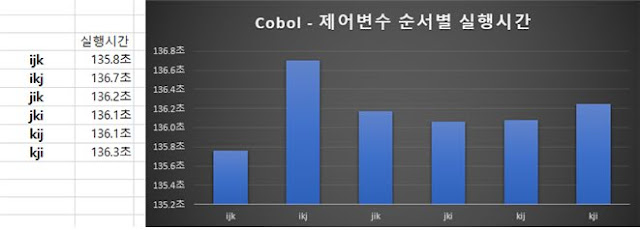
앞에 3개의 실험언어에서는 2000*2000행렬을 대상으로 실험을 진행했으나 Cobol에서는 500*500행렬을 대상으로 실험을 수행했다. 왜냐하면, 앞의 언어와 비교했을때 너무 느렸기 때문이다. 500*500행렬의 곱을 수행했을때 Cobol은 약 136초가 걸렸다. 500*500행렬은 약 1.25억 번의 곱셈연산을 수행하는데, 2000*2000행렬은 80억 번의 곱셈연산을 수행한다. 게다가 500*500행렬을 대상으로 실험을 실행했으나, 각 실험 결과에 있어서 유의미한 차이를 얻을 수 없었기 때문에 500*500으로 하나 2000*2000으로 하나 별 차이가 없을 것으로 예상했다. 앞의 실험결과와 전혀 다른 양상을 보이는데, 원인을 알 수가 없었다.
Common Lisp의 행렬 연산

cobol로 실험하면서 ‘설마 lisp이 cobol보다 느리겠어?’라는 생각을 잠깐 했었는데, 역시 불길한 예감은 잘 빗나가지 않는다.

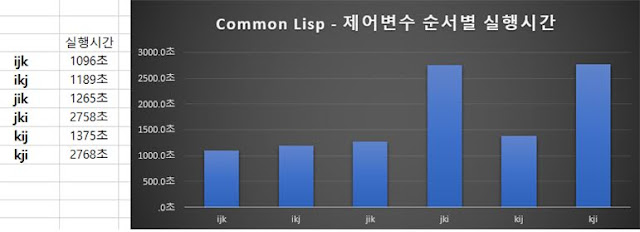
lisp도 cobol과 같은 이유 때문에 500*500 행렬을 대상으로 실험을 진행하였다. 실행시간이 한 술 더 뜨는건 덤이다. 위에서 먼저 진행했던 실험에 따르면, row major언어는 ikj와 kij에서 우수한 성능을 보여주었고, jki와 kji에서 아주 낮은 성능을 보여주었다. Common Lisp의 경우에는 row major와 같이 jki와 kji에서 낮은 성능을 보여주었기 때문에 row major의 성격을 띄고 있을 확률이 높아 보이지만, ikj와 kij가 유의미하게 좋은 성능을 내고 있지 않기 때문에 Common lisp이 row major의 방법으로 설계되었다고 단정짓기에는 무리가 있어 보인다.
결론
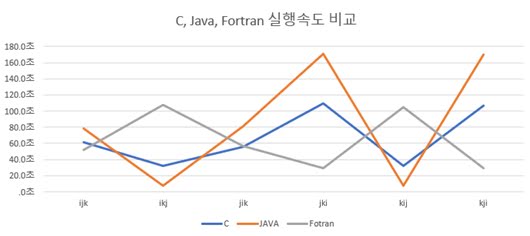
C와 Java는 동일하게 row major의 성격을 띄기 때문에 유사한 그래프 패턴을 보임을 알 수 있고, Fortran은 column major이기 때문에 정 반대의 그래프 패턴을 보이는 것을 확인할 수 있다. 이 실험은 내가 학교다니던 시절에 전공수업 과제로 했던것을 정리하여 포스팅한 것인데, 아직도 cobol과 lisp의 구조를 확실하게 밝혀내지 못했다.
추가실험: Data Locality를 더 크게하면?
지금까지의 실험에서는 row major인지 column major인지에 따라서 프로그램이 데이터가 담긴 공간에 접근할 때에 걸리는 시간차이 때문에 다차원 배열에서 데이터에 접근할 때에 성능차이가 발생하는 것을 관찰하였다. 그렇다면, 프로그램이 더 적은 범위만큼만 순회하면 동일한 횟수만큼 연산을 해도 더 높은 성능을 낼 수 있지 않을까? 라는 생각에서 간단한 실험을 진행해 봤다. C언어에서는 2000*2000의 행렬의 곱하기 연산을 수행했기 때문에 총 80억 번의 연산을 약 60초에 걸쳐서 수행한 것을 발견했다. 그렇다면, 200*200행렬의 곱을 수행하면 8백만 번의 곱하기 연산을 수행하는데, 이 것을 1천번 반복하여 마찬가지로 80억 번을 수행하면 의미있는 성능향상을 도출해 낼 수 있을까?

위 사진은 2000*2000행렬 곱셈 연산을 1번 수행한 것이다. 아래 사진은 200*200행렬 곱셈 연산을 1000번 수행한 것이다.

행렬의 곱하기 연산을 수행하는 3중 for문의 제어변수의 순서를 동일하게 유지한 채로 80억 번의 곱하기 연산을 동일하게 수행하였다. 동일한 알고리즘을 사용하였지만, 프로그램이 데이터를 얻기 위해서 주소공간에 접근할 때 더 인접한 지역에서 데이터를 갖고 오게 되므로 data locality가 증가하여 연산시간이 줄어든 것으로 생각할 수 있다.
내친김에 한 번 더 해보기로 했다. 이번에는 20*20행렬 1백만 번이다. 마찬가지로 총 곱하기 연산은 80억 번으로 동일하다.

근소한 차이지만 data locality가 조금 더 증가함으로 인해서 측정 시간이 더 짧아진 것을 확인할 수 있다.
이 실험은 다음 환경에서 수행되었다.
C : Visual Studio 2010 Express
Java : Eclipse Jee 2018-09
- jdk 1.8.0_181
Fortran : Code::Blocks 17.12
- MinGW 64bit
COBOL : OpenCobol IDE 4.7.6
Lisp : GNU CLISP 2.49
- Lispworks Personal edition 6.1.1