여러개의 지역에서 동일한 프로그램을 사용한다고 해도, 작업자의 부주의로 인해서 컬럼 사이즈나 not null등이 달라질 수 있다.
그런 경우에 프로그램의 무결성 유지를 위하여 기준이 되는 하나의 스키마를 세워서 통일시키는 일이 필요하다.
하지만 수백, 수천개의 컬럼들을 일일이 비교하는 데에는 상당한 무리가 따르기 때문에 아주 쉽고 간단하게 스키마를 비교할 수 있는 스크립트를 작성했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SELECT
A.TABLE_NAME || '.' || A.COLUMN_NAME || ' ' ||
CASE -- DATA_TYPE
WHEN DATA_TYPE IN ('CHAR', 'VARCHAR', 'VARCHAR2') THEN DATA_TYPE || '(' || DATA_LENGTH || ')'
WHEN DATA_TYPE IN ('NUMBER') THEN DATA_TYPE || DECODE(DATA_PRECISION, NULL, '', '(' || DATA_PRECISION || DECODE(DATA_SCALE, 0, ')', ',' || DATA_SCALE || ')') )
ELSE DATA_TYPE
END
|| ' '
|| DECODE(NULLABLE, 'Y', 'N', NULLABLE) -- NULLABLE
|| DECODE((SELECT COUNT(1) FROM USER_CONS_COLUMNS CC, USER_CONSTRAINTS C WHERE CC.CONSTRAINT_NAME = C.CONSTRAINT_NAME AND C.CONSTRAINT_TYPE='P' AND CC.TABLE_NAME = A.TABLE_NAME AND CC.COLUMN_NAME = A.COLUMN_NAME), 1, 'Y', 'N') -- IS_PK
|| DECODE((SELECT COUNT(1) FROM USER_IND_COLUMNS C WHERE A.TABLE_NAME = C.TABLE_NAME AND A.COLUMN_NAME = C.COLUMN_NAME), 1, 'Y', 'N') SCHEMA-- IS_IDX
FROM USER_TAB_COLUMNS A, USER_TABLES B
WHERE A.TABLE_NAME = B.TABLE_NAME
ORDER BY SCHEMA;
위의 sql을 실행시키게 되면 다음과 같은 결과를 얻을 수 있다.
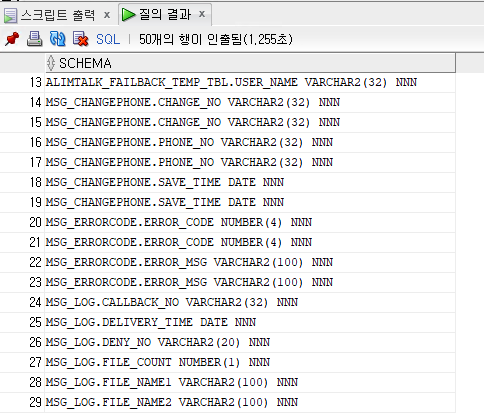
비교를 할 양쪽 DB에다가 동일하게 위의 sql을 실행시킨다.
그리고 그 결과를 WinMerge의 양쪽에 붙여넣기를 한다.
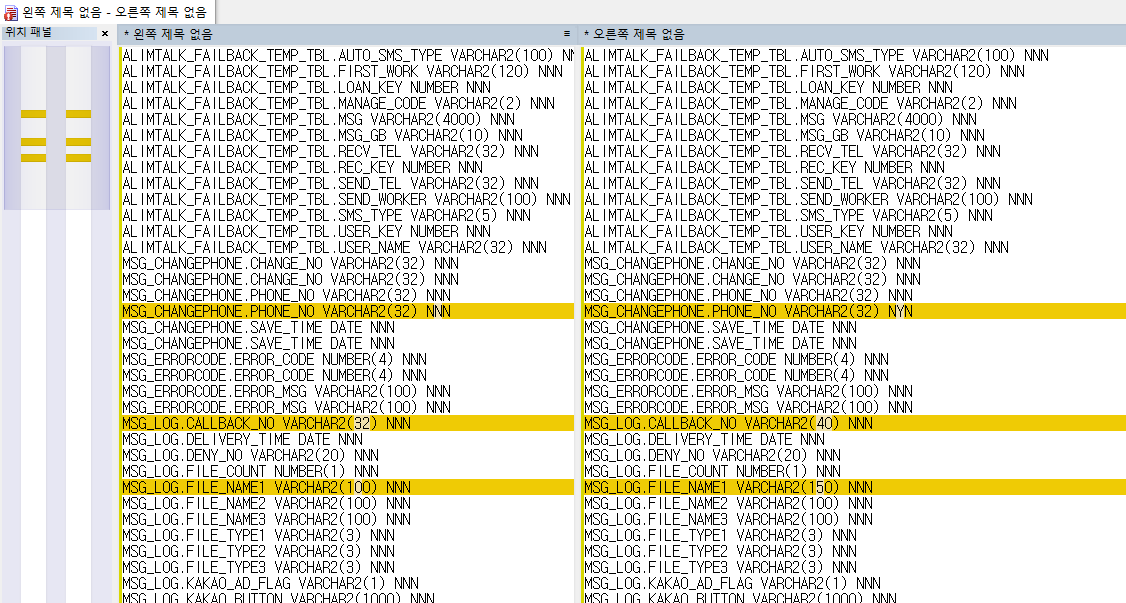
어느 부분이 어떻게 다른지 강조까지 해주므로 쉽게 스키마를 비교할 수 있다.
WinMerge에서는 최대 3개의 파일의 동시비교를 지원하므로 3개의 DB까지는 쉽게 비교할 수 있지만, 그 보다 많은 수의 DB를 비교하기에는 약간의 번거로움이 따른다.
이 경우에는 WinMerge대신에 엑셀을 사용하면 된다.
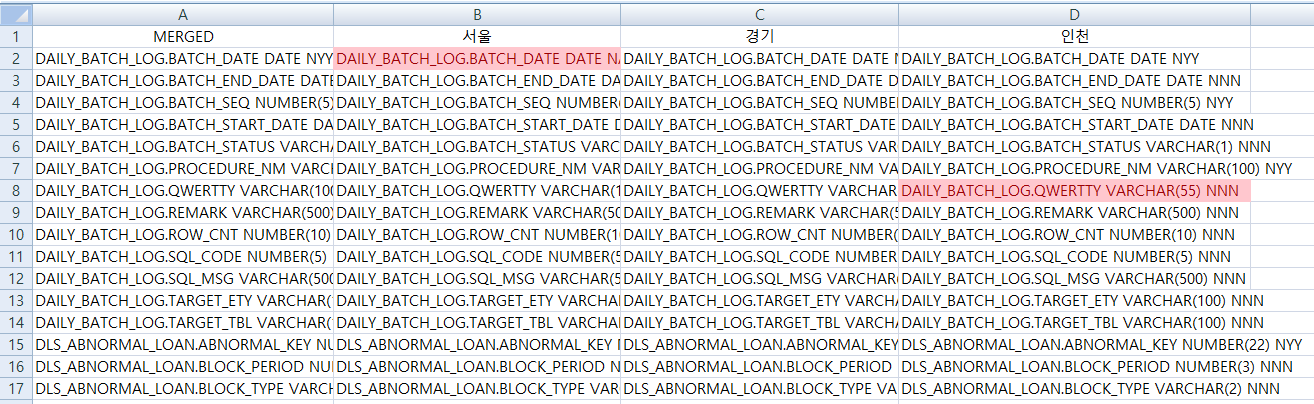
동일한 sql의 실행결과를 열 단위로 붙여넣고, 엑셀의 조건부 서식을 지정하여 A열을 기준으로 A열과 B열, A열과 C열, A열과 D열… 이런 식으로 비교를 하면 WinMerge에서 비교해주는 것과 유사하게 더 여러개의 DB 스키마를 비교할 수 있다.
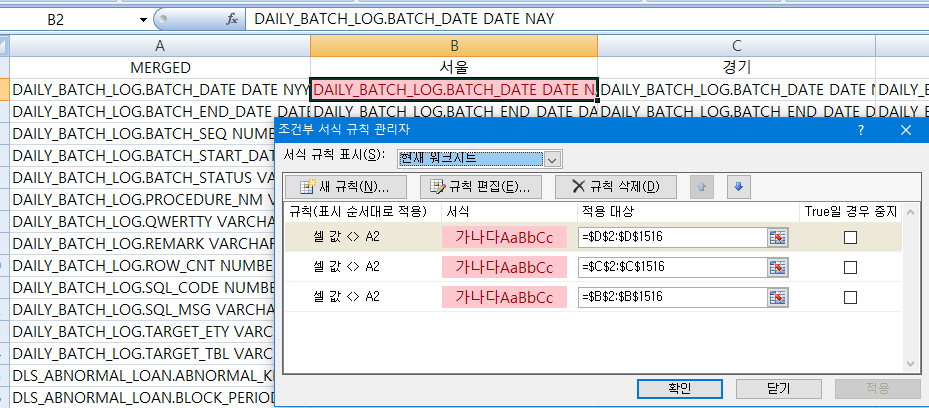
조건부 서식은 이런 식으로 입력하면 된다.