새로운 것을 배우는 데에 집중하면 가끔 아주 기본적인 것을 간과하는 멍청한 짓을 하기도 한다.
사직연산이 혼합된 계산식에서는 더하기, 빼기 연산은 우선순위가 낮고 곱하기, 나누기 연산은 우선순위가 더 높다는 것을 예를 들 수 있겠다.
그와 마찬가지로 코드를 작성할 때에는 변수 이름을 중복시키면 안된다는 것은 아주 자명한 상식이지만, 내가 Spring Batch를 공부하느라 저질렀던 멍청한 짓을 공유하도록 한다.
Spring Batch는 기본적으로 Job, Step, Tasklet이라는 단위로 동작한다. 그래서 하나의 어플리케이션 안에 여러개의 Job이 있을 수 있고, 각각의 job들은 여러개의 Step을, Step들은 여러개의 Tasklet을 포함할 수 있다.
이런 Spring Batch의 계층적인 구조를 보면 관심사의 범위에 따라서 패키지를 나눌 수 있다는 생각을 할 수 있다.
여러개의 Job이 있을때, Job내부의 Step과 Tasklet들은 다른 Job과 공유하지 않는 독립적인 영역이기 때문에 Job단위로 패키지를 나누면 구분하기 쉬울 것이다.
그래서 sample job을 하나 만들어서 정상적으로 동작하는 것을 확인하고, sample job을 그대로 복사해서 sample2 job을 만들었다.
그래서 두 job의 패키지는 다음과 같다.
1
package collectedgarbage.DBtoDBMigrator.batch.sample;
1
package collectedgarbage.DBtoDBMigrator.batch.sample2;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
package collectedgarbage.DBtoDBMigrator.batch.sample;
@Configuration
@RequiredArgsConstructor
public class SampleConfig {
@Resource(name = "source")
private final DataSource source;
@Resource(name = "dest")
private final DataSource dest;
public static int pageSize = 10000;
@Bean
public PagingQueryProvider provider() throws Exception {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setDataSource(source);
provider.setSelectClause("sample_key, sample_data");
provider.setFromClause("from sample");
provider.setSortKeys(Map.of("sample_key", Order.ASCENDING));
return provider.getObject();
}
@Bean
public JdbcPagingItemReader<Sample> reader() throws Exception {
return new JdbcPagingItemReaderBuilder<Sample>()
.dataSource(source)
.pageSize(pageSize)
.queryProvider(provider())
.rowMapper(new BeanPropertyRowMapper<>(Sample.class))
.name("jdbcPagingItemReader")
.build();
}
@Bean
public SampleProcessor processor() {
return new SampleProcessor();
}
@Bean
public JdbcBatchItemWriter<Sample> writer() {
return new JdbcBatchItemWriterBuilder<Sample>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO sample (sample_key, sample_data) VALUES (:sampleKey, :sampleData)")
.dataSource(dest)
.build();
}
@Bean
public Job sample(JobRepository jobRepository, SampleListener listener, Step step1) {
return new JobBuilder("sample", jobRepository)
.listener(listener)
.flow(step1)
.end()
.build();
}
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager, JdbcBatchItemWriter<Sample> writer) throws Exception {
return new StepBuilder("step1", jobRepository)
.<Sample, Sample> chunk(pageSize, transactionManager)
.reader(reader())
.processor(processor())
.writer(writer)
.build();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
package collectedgarbage.DBtoDBMigrator.batch.sample2;
@Configuration
public class Sample2Config {
@Resource(name = "source")
private DataSource source;
@Resource(name = "dest")
private DataSource dest;
public static int pageSize = 10000;
@Bean
public PagingQueryProvider provider() throws Exception {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setDataSource(source);
provider.setSelectClause("sample_key, sample_data");
provider.setFromClause("from sample2");
provider.setSortKeys(Map.of("sample_key", Order.ASCENDING));
return provider.getObject();
}
@Bean
public JdbcPagingItemReader<Sample2> reader() throws Exception {
return new JdbcPagingItemReaderBuilder<Sample2>()
.dataSource(source)
.pageSize(pageSize)
.queryProvider(provider())
.rowMapper(new BeanPropertyRowMapper<>(Sample2.class))
.name("jdbcPagingItemReader")
.build();
}
@Bean
public Sample2Processor processor() {
return new Sample2Processor();
}
@Bean
public JdbcBatchItemWriter<Sample2> writer() {
return new JdbcBatchItemWriterBuilder<Sample2>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO sample2 (sample_key, sample_data) VALUES (:sampleKey, :sampleData)")
.dataSource(dest)
.build();
}
@Bean
public Job sample2(JobRepository jobRepository, Sample2Listener listener, Step step1) {
return new JobBuilder("sample2", jobRepository)
.listener(listener)
.flow(step1)
.end()
.build();
}
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager, JdbcBatchItemWriter<Sample2> writer) throws Exception {
return new StepBuilder("step1", jobRepository)
.<Sample2, Sample2> chunk(pageSize, transactionManager)
.reader(reader())
.processor(processor())
.writer(writer)
.build();
}
}
위의 두 Config클래스는 job name과 테이블 이름을 제외하고 완벽하게 동일하다. 하지만 위의 두 클래스가 하나의 프로젝트 안에 동시에 존재하면 프로그램 자체가 고장나 버린다.
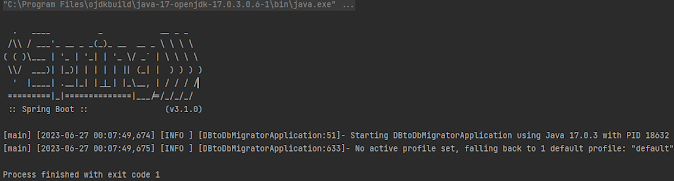
아무 문제도 없어 보이지만, 위의 코드를 실행하면 위와 같은 결과를 보여주며 아무것도 하지 않고 프로그램이 종료되어 버린다.
왜냐하면 bean객체는 메소드의 이름을 자동으로 빈 이름으로 지정하는데, 두 클래스는 복붙으로 작성된 코드이므로 모든 bean객체의 이름이 완벽하게 동일하기 때문이다.
bean객체도 일반적인 변수와 마찬가지로 객체명이 동일하지 않아야 함이 분명하지만, IDE가 bean객체명의 중복을 지적하지 않기 때문에 이런 멍청한 짓을 하게 되었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
package collectedgarbage.DBtoDBMigrator.batch.sample2;
@Configuration
public class Sample2Config {
@Resource(name = "source")
private DataSource source;
@Resource(name = "dest")
private DataSource dest;
public static int pageSize = 10000;
@Bean
public PagingQueryProvider provider2() throws Exception {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setDataSource(source);
provider.setSelectClause("sample_key, sample_data");
provider.setFromClause("from sample2");
provider.setSortKeys(Map.of("sample_key", Order.ASCENDING));
return provider.getObject();
}
@Bean
public JdbcPagingItemReader<Sample2> reader2() throws Exception {
return new JdbcPagingItemReaderBuilder<Sample2>()
.dataSource(source)
.pageSize(pageSize)
.queryProvider(provider2())
.rowMapper(new BeanPropertyRowMapper<>(Sample2.class))
.name("jdbcPagingItemReader")
.build();
}
@Bean
public Sample2Processor processor2() {
return new Sample2Processor();
}
@Bean
public JdbcBatchItemWriter<Sample2> writer2() {
return new JdbcBatchItemWriterBuilder<Sample2>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO sample2 (sample_key, sample_data) VALUES (:sampleKey, :sampleData)")
.dataSource(dest)
.build();
}
@Bean
public Job sample2(JobRepository jobRepository, Sample2Listener listener, Step step1) {
return new JobBuilder("sample2", jobRepository)
.listener(listener)
.flow(step1)
.end()
.build();
}
@Bean
public Step step2(JobRepository jobRepository, PlatformTransactionManager transactionManager, JdbcBatchItemWriter<Sample2> writer) throws Exception {
return new StepBuilder("step1", jobRepository)
.<Sample2, Sample2> chunk(pageSize, transactionManager)
.reader(reader2())
.processor(processor2())
.writer(writer)
.build();
}
}
그래서 두 번째 클래스를 이런식으로 메소드 이름을 살짝씩 바꿔주면 내가 의도한대로 정상적으로 동작한다.
내가 지금은 Spring Batch를 공부하고는 있지만, 지금 당장 필요한 것은 아니고 나중에 필요할 것 같아서 미리 공부겸, 자주 쓰는 템플릿을 만들어서 github에 올려두려고 한 것인데, github에 올리려고 하다보니 클래스이름에 sample을 넣다보니 이런 일이 발생했다.
샘플용 코드라고 하더라도 객체이름을 성의있게 지어야 하는 이유를 새삼스럽게 체감했다.